|
Minghui Hu
He is currently a researcher at
SpellBrush We are hiring! Drop me an email if you're passionate about anime, game and (or) generative models. Let us shape the future of Anime Generation and Game Design together.,
previously interned at Sensetime Research and
MiniMax.
He received his Ph.D and MSc. from Nanyang Technological University, Singapore, under the supervision of Prof. P. N. Suganthan.
Concurrent with his doctoral research, he served as a researcher at Temasek Laboratories @ NTU, where he conducted research under the supervision of Dr. Sirajudeen s/o Gulam Razul.
He has had the privilege of collaborating closely with Prof. Tat-Jen Cham and Prof. Dacheng Tao from College of Computing and Data Science, NTU.
Meanwhile, Dr. Chuanxia Zheng from VGG, University of Oxford, and Dr. Chaoyue Wang offered invaluable mentorship and support to his academic development.
Mail: e200008 [at] e.ntu.edu.sg
Google Scholar /
Github /
LinkedIn
|

|
|
Publications
His research focuses on visual generative models, including the pre-training and post-training of foundation models.
His recent work includes scalable methods for pre-training conditional generation models, such as text- and visual-conditioned models for image, video, and 3D asset generation. Additionally, he explores flexible post-training techniques aimed at accelerating distillation and preference alignment.
|
|
|
|
|
Semantix: An Energy-guided Sampler for Semantic Style Transfer
Huiang He *,
Minghui Hu *,
Chuanxia Zheng,
Chaoyue Wang,
Tat-Jen Cham
ICLR, 2025
OpenReview
We propose a energy-guided sampler for semantic style transfer.
* equal contribution
|
|
|
|
Connecting Consistency Distillation to Score Distillation for Text-to-3D Generation
Zongrui Li *,
Minghui Hu *,
Qian Zheng,
Xudong Jiang,
ECCV, 2024
project page
/
arXiv
/
code
We analyze current SDS-based text-to-3D generation methods and propose an improved version with a bright normalizing trick for Gaussian Splatting.
* equal contribution
|
|
|
|
|
Trajectory Consistency Distillation
Jianbin Zheng *,
Minghui Hu *,
Zhongyi Fan,
Chaoyue Wang,
Changxing Ding,
Dacheng Tao,
Tat-Jen Cham
Tech Report, 2024
project page
/
arXiv
/
code
/
HF Model
/
HF Space
We distill a consistency model based on diffusion trajectory to improve the sample quality.
* equal contribution
|
|
|
|
|
One More Step: A Versatile Plug-and-Play Module for Rectifying Diffusion Schedule Flaws and Enhancing Low-Frequency Controls
Minghui Hu,
Jianbin Zheng,
Chuanxia Zheng,
Chaoyue Wang,
Dacheng Tao,
Tat-Jen Cham
CVPR, 2024
project page
/
arXiv
/
code
/
HF Model
/
HF Space
We develop a versatile plug-and-play module to fix the scheduler flaws for diffusion models.
|
|
|
|
|
Cocktail🍸: Mixing Multi-Modality Controls for Text-Conditional Image Generation
Minghui Hu,
Jianbin Zheng,
Daqing Liu,
Chuanxia Zheng,
Chaoyue Wang,
Dacheng Tao,
Tat-Jen Cham
NeurIPS, 2023
project page
/
arXiv
/
code
/
HF Model
We develop a generalized HypreNetwork for multi-modality control based on text-to-image generative model.
|
|
|
|
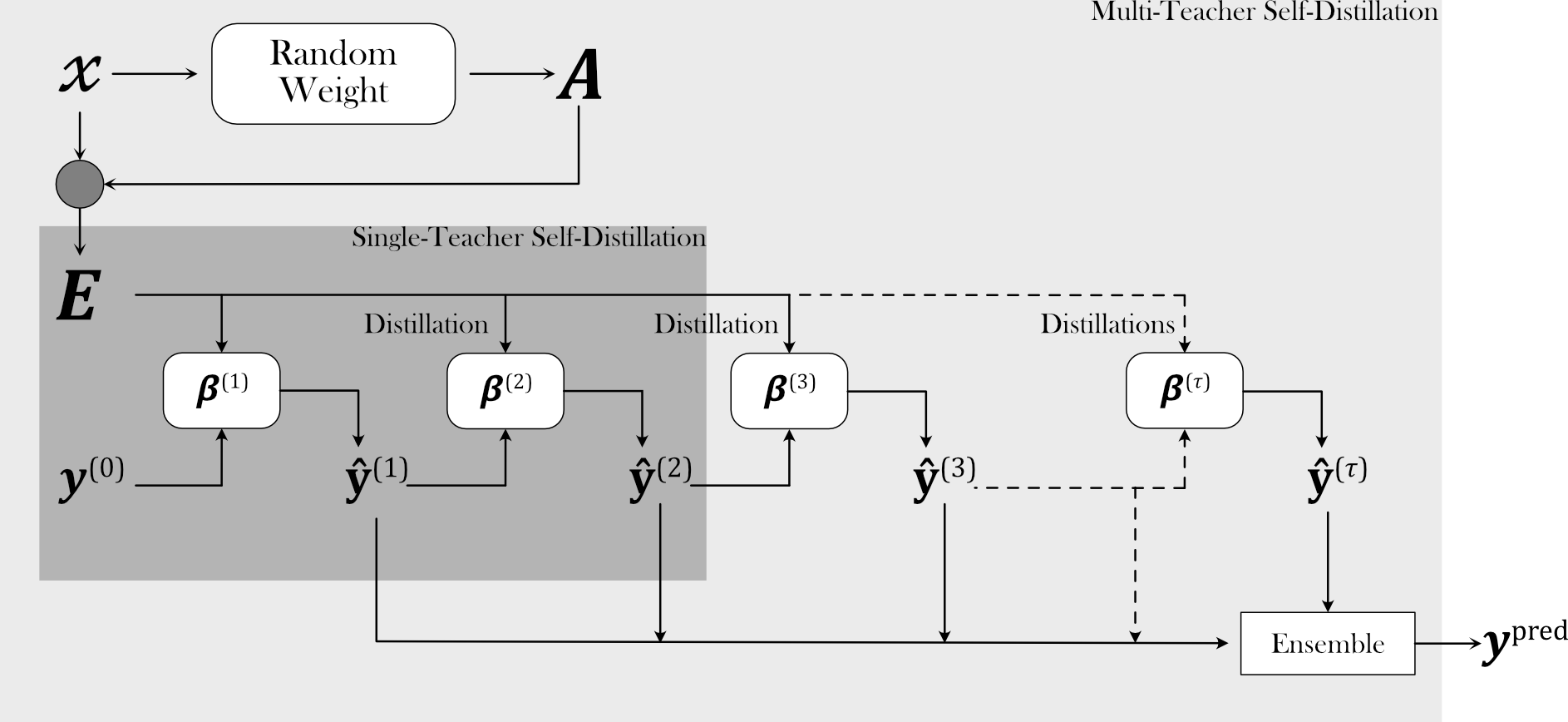
Self-Distillation for Randomized Neural Networks
Minghui Hu,
Ruobin Gao,
P.N.Suganthan,
T-NNLS
IEEE
/
Code
We integrate self-distillation into the randomized neural network to improve the generalization performance.
|
|
|
|
|
MMoT: Mixture-of-Modality-Tokens Transformer for Composed Multimodal Conditional Image Synthesis
Jianbin Zheng,
Daqing Liu,
Chaoyue Wang,
Minghui Hu,
Zuopeng Yang,
Changxing Ding,
Dacheng Tao,
IJCV
project page
/
arXiv
We introduce a Mixture-of-Modality-Tokens Transformer (MMoT) that adaptively fuses fine-grained multimodal control signals for multi-modality image generation.
|
|
|
|
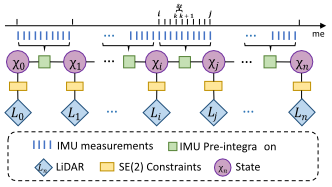
Versatile LiDAR-Inertial Odometry with SE(2) Constraints for Ground Vehicles
Jiaying Chen,
Han Wang,
Minghui Hu,
P.N.Suganthan,
RA-L & IROS, 2023
IEEE
We propose a hybrid LiDAR-inertial SLAM framework that leverages both the on-board perception system and prior information such as motion dynamics to improve localization performance.
|
|
|
|
|
Class-Incremental Learning on Multivariate Time Series Via Shape-Aligned Temporal Distillation
Zhongzheng Qiao,
Minghui Hu,
Xudong Jiang,
P.N.Suganthan,
Ramasamy Savitha,
ICASSP, 2023
IEEE
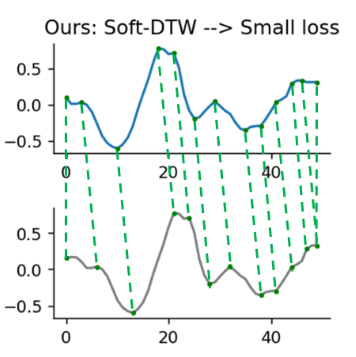
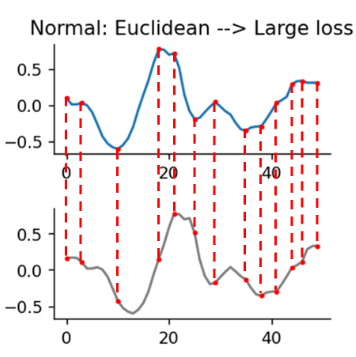
We propose to exploit Soft-Dynamic Time Warping (Soft-DTW) for knowledge distillation, which aligns the feature maps along the temporal dimension before calculating the discrepancy.
|
|
|
|
|
Unified Discrete Diffusion for Simultaneous Vision-Language Generation
Minghui Hu,
Chuanxia Zheng,
Zuopeng Yang,
Tat-Jen Cham,
Chaoyue Wang,
Dacheng Tao,
P.N.Suganthan
ICLR, 2023
project page
/
arXiv
/
PDF
We construct a unified discrete diffusion model for simultaneous vision-language generation.
|
|
|
|
|
Representation Learning Using Deep Random Vector Functional Link Networks for Clustering
Minghui Hu,
P.N.Suganthan
PR
Elsevier
We use manifold regularisation to learn the representation from the randomised networks.
|
|
|
|
|
Global Context with Discrete Diffusion in Vector Quantised Modelling for Image Generation
Minghui Hu,
Yujie Wang,
Tat-Jen Cham,
Jianfei Yang,
P.N.Suganthan
CVPR, 2022
arXiv
/
PDF
Instead of AutoRegresive Transformers, we use Discrete Diffusion Model to obtain a better global context for image generation.
|
Academic Services
Conference Reviewer
| CVPR | 2022 - 2025 |
| ICCV | 2023 |
| ECCV | 2024 |
| NeurIPS | 2023, 2024 |
| ICLR | 2023 - 2025 |
| ICML | 2025 |
| ACCV | 2024 |
| ACM MM | 2024 |
| ICASSP | 2023, 2024 |
| IJCNN | 2020 - 2024 |
Journal Reviewer
T-PAMI, T-NNLS, T-Cyb, IJCV, PR, InfoFusion, NeuNet, Neucom, ASoC, EAAI
|
| |